
การทำ SEO ในปัจจุบันต้องอาศัยการวิเคราะห์ข้อมูลจำนวนมาก ซึ่งการทำด้วยมืออาจใช้เวลานานและเกิดข้อผิดพลาดได้ง่าย บทความนี้จะแนะนำวิธีการใช้ Python เพื่อช่วยในการดึงข้อมูล SEO จากเว็บไซต์และบันทึกลง Google Sheets แบบอัตโนมัติ เหมาะสำหรับ SEO specialists และ Digital Marketers ที่ต้องการเพิ่มประสิทธิภาพในการทำงาน
สิ่งที่ต้องเตรียม
- Python (version 3.6 ขึ้นไป)
- Google Cloud Console Account
- Google Sheets ที่พร้อมใช้งาน
- Text Editor หรือ IDE (แนะนำ VS Code)
Note: วิธีการดาวน์โหลดและติดตั้ง Python
Step 1: เตรียม Google Sheets API
ก่อนเริ่มเขียนโค้ด เราต้องเตรียม API และ Credentials ให้พร้อม:
1. ไปที่ Google Cloud Console (https://console.cloud.google.com)
2. เสร็จแล้วทำการสร้างโปรเจคใหม่และตั้งชื่อโปรเจคท์ให้เรียบร้อยครับ
3. เสร็จแล้วตรงช่องเสิร์ชให้ค้นหา Google Sheets API และทำการเปิดใช้งาน (Enable)
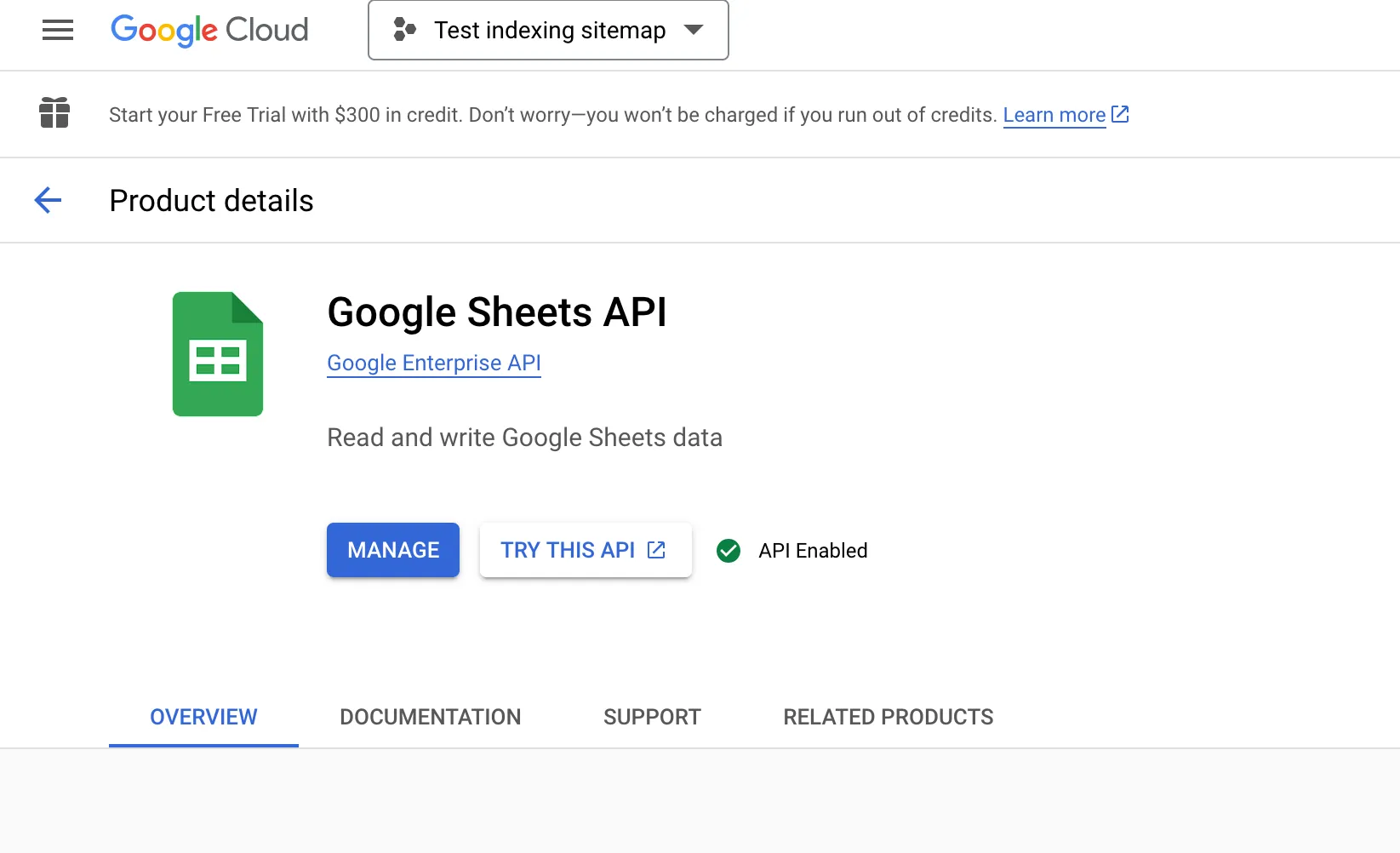
4. สร้าง Credentials โดยคลิก
- "+CREATE CREDENTIALS"
- จากนั้น "OAuth client ID"
- เสร็จแล้วเลือก application แบบ "Desktop app"
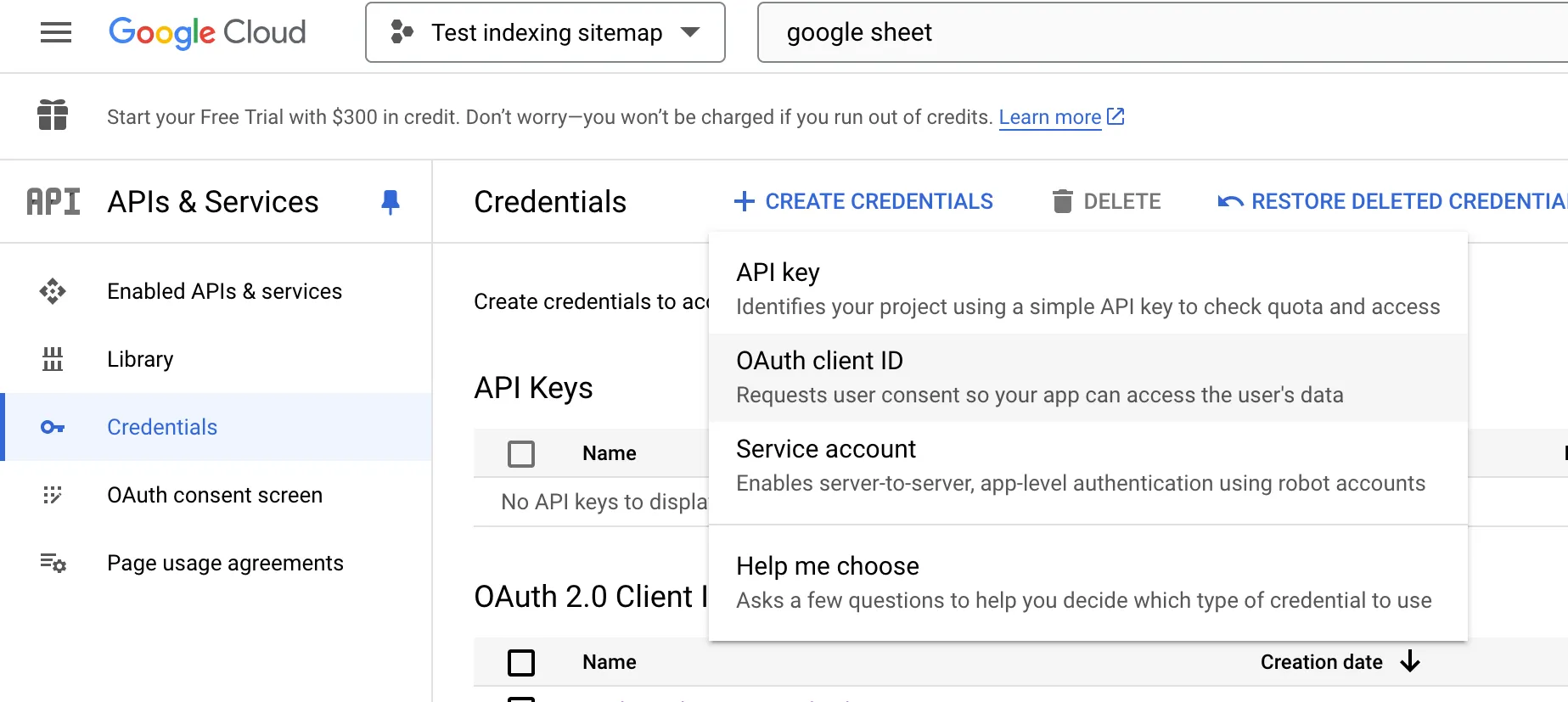
เลือก Desktop app
ตั้งชื่อแล้ว "CREATE" ได้เลยครับ
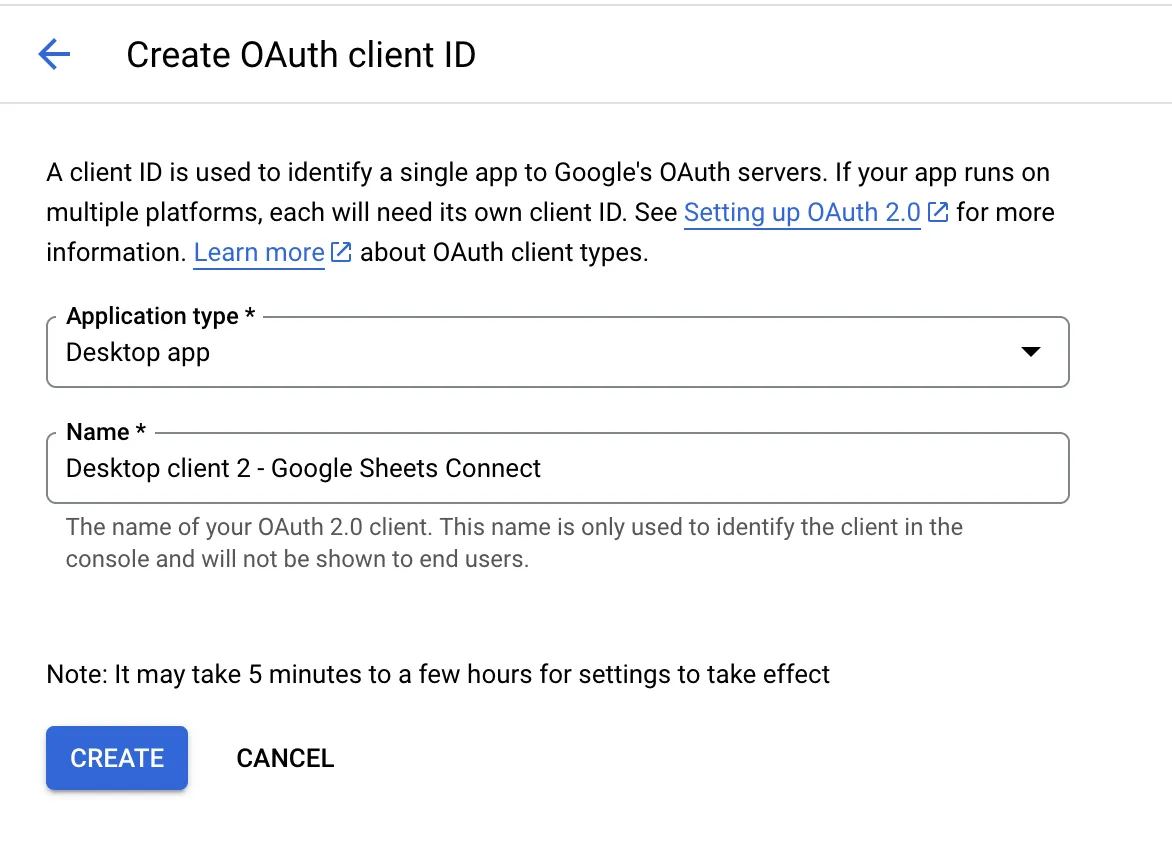
เรียบร้อย
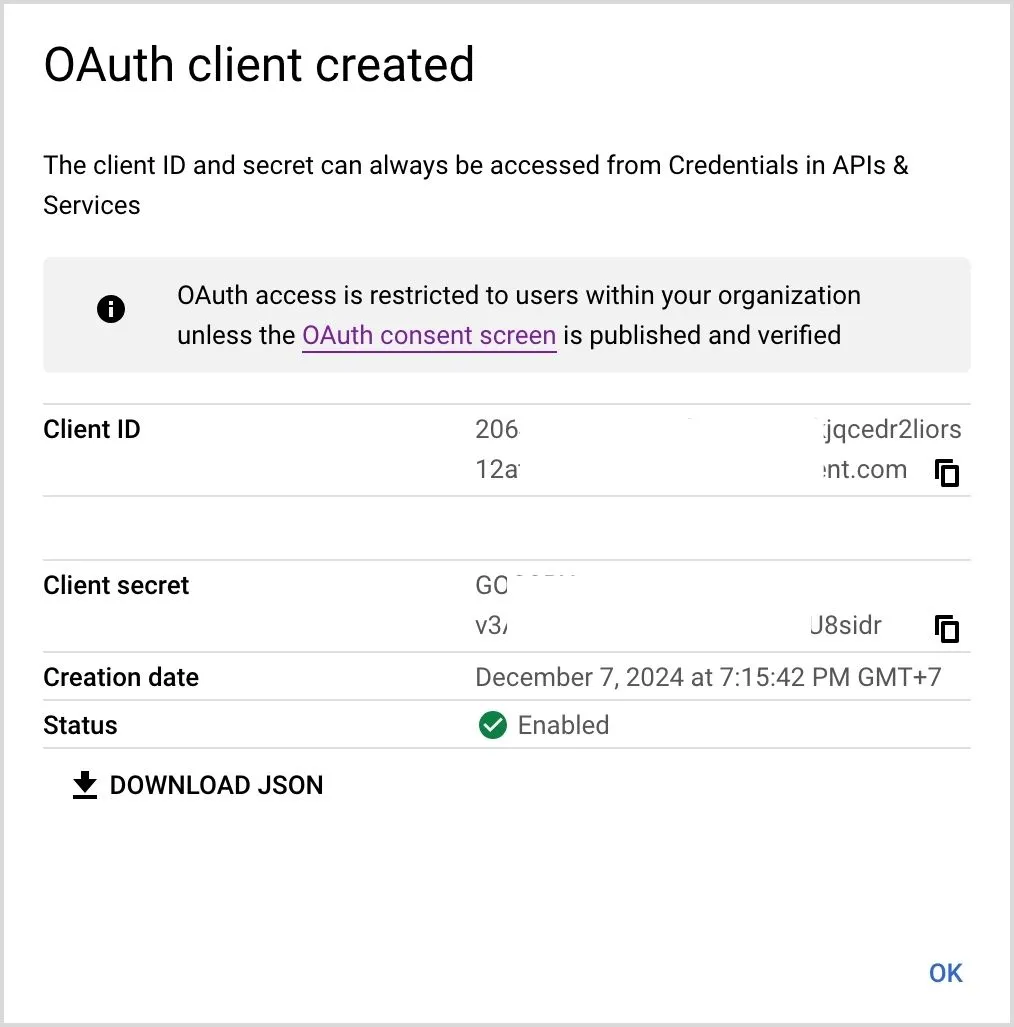
เสร็จแล้วดาวน์โหลดไฟล์ client_secrets.json เก็บไว้ในโฟลเดอร์โปรเจคท์
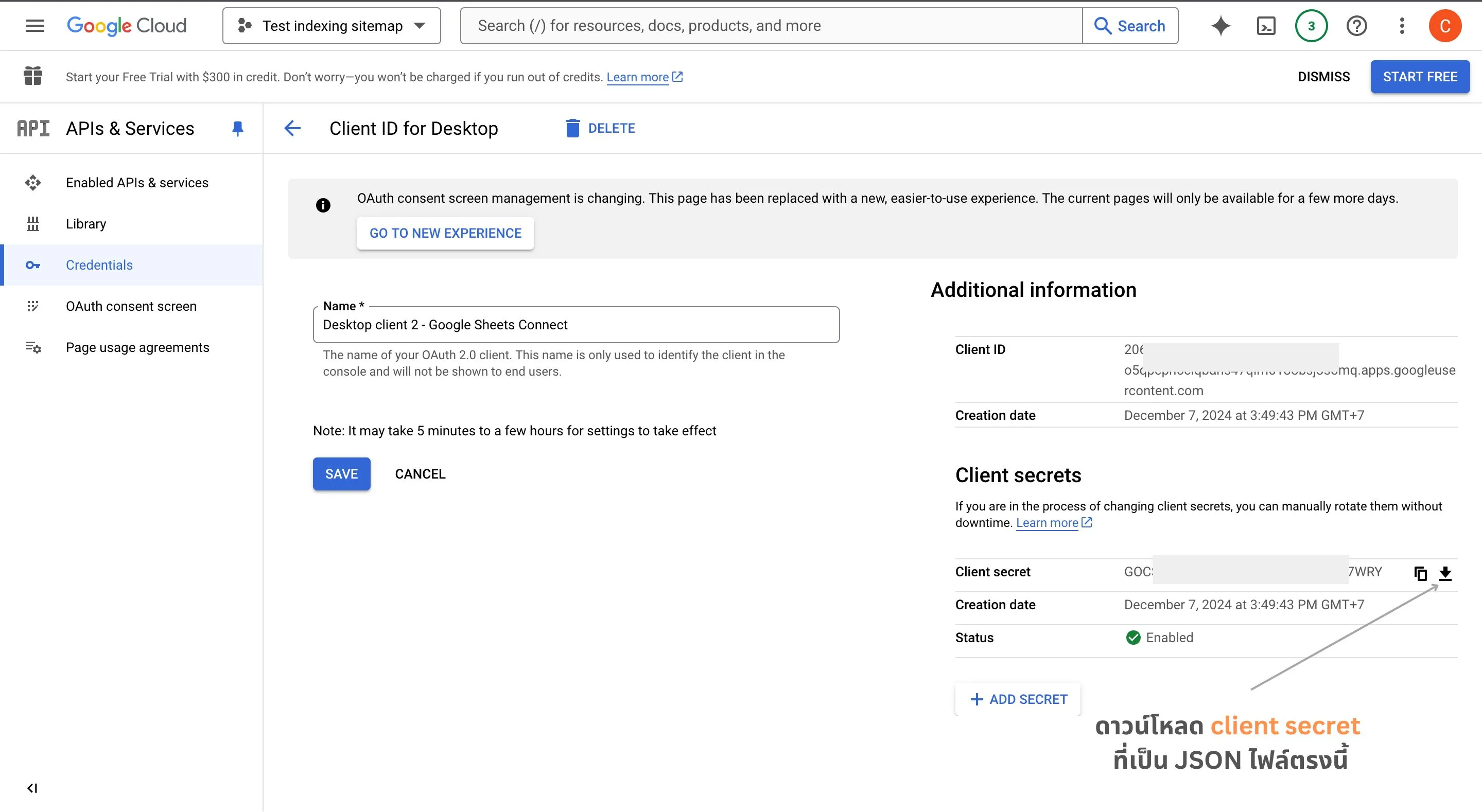
ทำการสร้างโปรเจคท์บน Google Cloud Console
เสร็จแล้วสร้าง Sheet ไฟล์เปล่า ๆ ของเราขึ้นมา โดยเราจะนำ Sheet ID นี่แหละครับไปใช้ในการเขียนโค้ดเพื่อเชื่อมต่อในลำดับถัดไปโดยในภาพ URL คือ
https://docs.google.com/spreadsheets/d/1cFMXiEOfeffRlr8Xenjz1IJHYX46Q0nUpLGF_ayPLuw
/edit?gid=0#gid=0เราจะได้ Sheet ID คือ 1cFMXiE...ayPLuw
โครงสร้างของโปรเจคท์
โปรเจคท์นี้จะสร้างโฟลเดอร์ชื่อโปรเจคท์ชื่อ python-seo แล้วจะมีไฟล์ 2 ไฟล์ในโฟลเดอร์คือ
- main.py: เป็นไฟล์สำหรับเขียน Python script นั่นเองครับ
- client_secrets.json: เป็นไฟล์ที่เก็บ credentials ต่าง ๆ ไว้ให้ Python สามารถพูดคุยกับ Google Sheets ได้ผ่าน API
└── python-seo
├── main.py
└── client_secrets.jsonStep 2: การติดตั้ง Libraries
เปิด Terminal และติดตั้ง packages ที่จำเป็น ด้วย package manager ของ Python อย่าง PIP
pip install requests beautifulsoup4 google-auth-oauthlib google-auth-httplib2 google-api-python-clientStep 3: เริ่มเขียนโค้ด
3.1 การ Import Libraries ที่จำเป็น
ทำการ import ไลบรารีที่จำเป็นต้องใช้ใน script นี้ครับ
import os
import requests
from bs4 import BeautifulSoup
from google.oauth2.credentials import Credentials
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
import pickle3.2 ดึงข้อมูลจากเว็บไซต์
ฟังก์ชันนี้ทำหน้าที่ดึงข้อมูล HTML จากเว็บไซต์ โดยใช้ User-Agent เพื่อป้องกันการถูกบล็อก
def scrape_website(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
return soup
else:
print(f"เกิดข้อผิดพลาด: {response.status_code}")
return None3.3 แยกข้อมูล SEO Tags ที่ต้องการ
ฟังก์ชันนี้จะแยกข้อมูล SEO ที่สำคัญจาก HTML ได้แก่ title, meta description, h1, h2, จำนวนลิงก์และรูปภาพ
def extract_seo_data(soup):
seo_data = {
'title': soup.title.text if soup.title else '',
'meta_description': soup.find('meta', {'name': 'description'})['content']
if soup.find('meta', {'name': 'description'}) else '',
'h1_tags': [h1.text for h1 in soup.find_all('h1')],
'h2_tags': [h2.text for h2 in soup.find_all('h2')],
'links': len(soup.find_all('a')),
'images': len(soup.find_all('img'))
}
return seo_data3.4 เชื่อมต่อ Google Sheets
ฟังก์ชันนี้จัดการการเชื่อมต่อกับ Google Sheets API และการจัดการ authentication
def connect_to_sheets():
SCOPES = ['https://www.googleapis.com/auth/spreadsheets']
creds = None
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'client_secrets.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
service = build('sheets', 'v4', credentials=creds)
return service3.5 อัพเดทข้อมูลลง Sheet
เขียนฟังก์ชันเพื่ออัปเดตข้อมูลที่ scrape ได้ลงบน Google Sheets เพื่อนำไปใช้งานต่อไป
def update_sheet(service, spreadsheet_id, range_name, values):
body = {
'values': values
}
result = service.spreadsheets().values().update(
spreadsheetId=spreadsheet_id,
range=range_name,
valueInputOption='USER_ENTERED',
body=body
).execute()
return result3.6 ฟังก์ชัน Main และการรันโปรแกรม
ในฟังก์ชันนี้จะลองลิสต์รายชื่อเว็บที่เราต้องการ scrape เพื่อนำข้อมูลมาเก็บลงบน Sheet และนำไปวิเคราะห์ต่อไป โดยตัวอย่างลองเลือกเว็บ SEO ระดับโลก
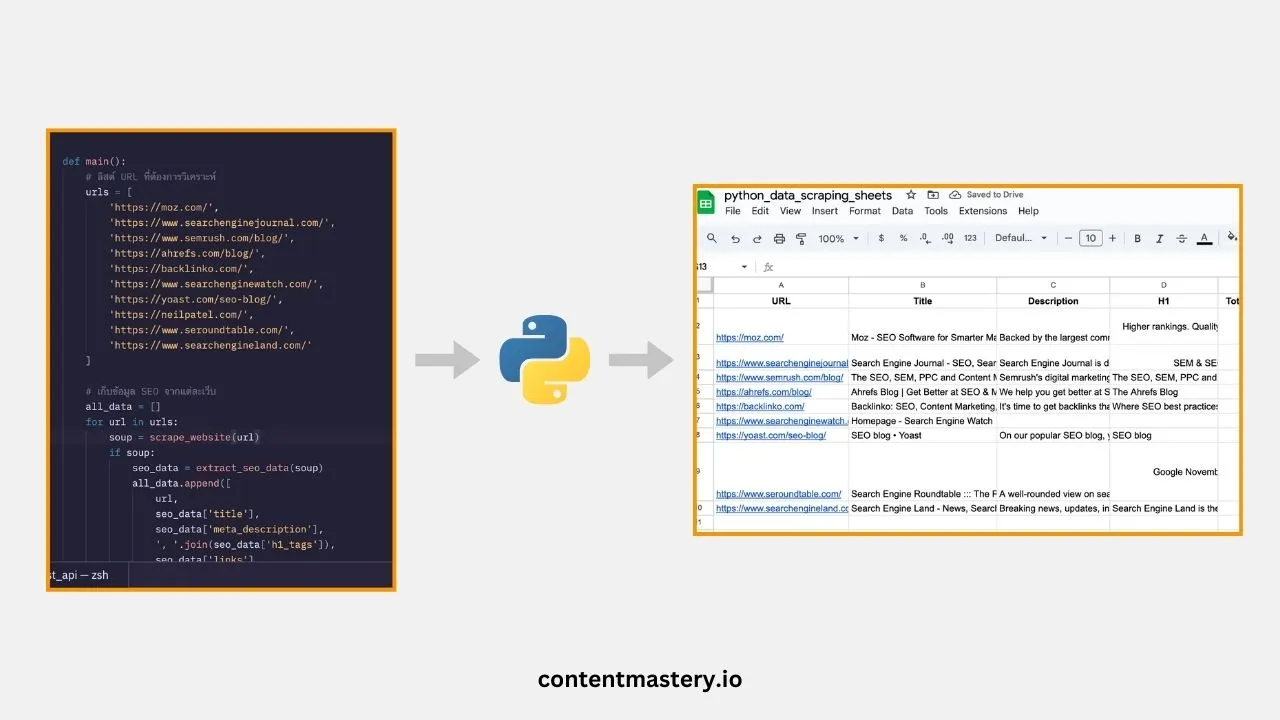
def main():
urls = [
'https://moz.com/',
'https://www.searchenginejournal.com/',
'https://www.semrush.com/blog/',
# เพิ่ม URLs ตามต้องการ
]
all_data = []
for url in urls:
soup = scrape_website(url)
if soup:
seo_data = extract_seo_data(soup)
all_data.append([
url,
seo_data['title'],
seo_data['meta_description'],
', '.join(seo_data['h1_tags']),
seo_data['links'],
seo_data['images']
])
service = connect_to_sheets()
SPREADSHEET_ID = 'YOUR_SPREADSHEET_ID' # ใส่ ID ของ Sheet ของคุณ
RANGE_NAME = 'Sheet1!A2:F'
update_sheet(service, SPREADSHEET_ID, RANGE_NAME, all_data)
if __name__ == '__main__':
main()จากนั้นทำการรันโค้ดด้วยคำสั่ง file_name.py เช่น ถ้าเราตั้งชื่อไฟล์ชื่อ main.py ก็รันเป็น python main.py
 ยืนยันตัวตนสำเร็จ
ยืนยันตัวตนสำเร็จ
เปิดดู Google Sheets ของเรา
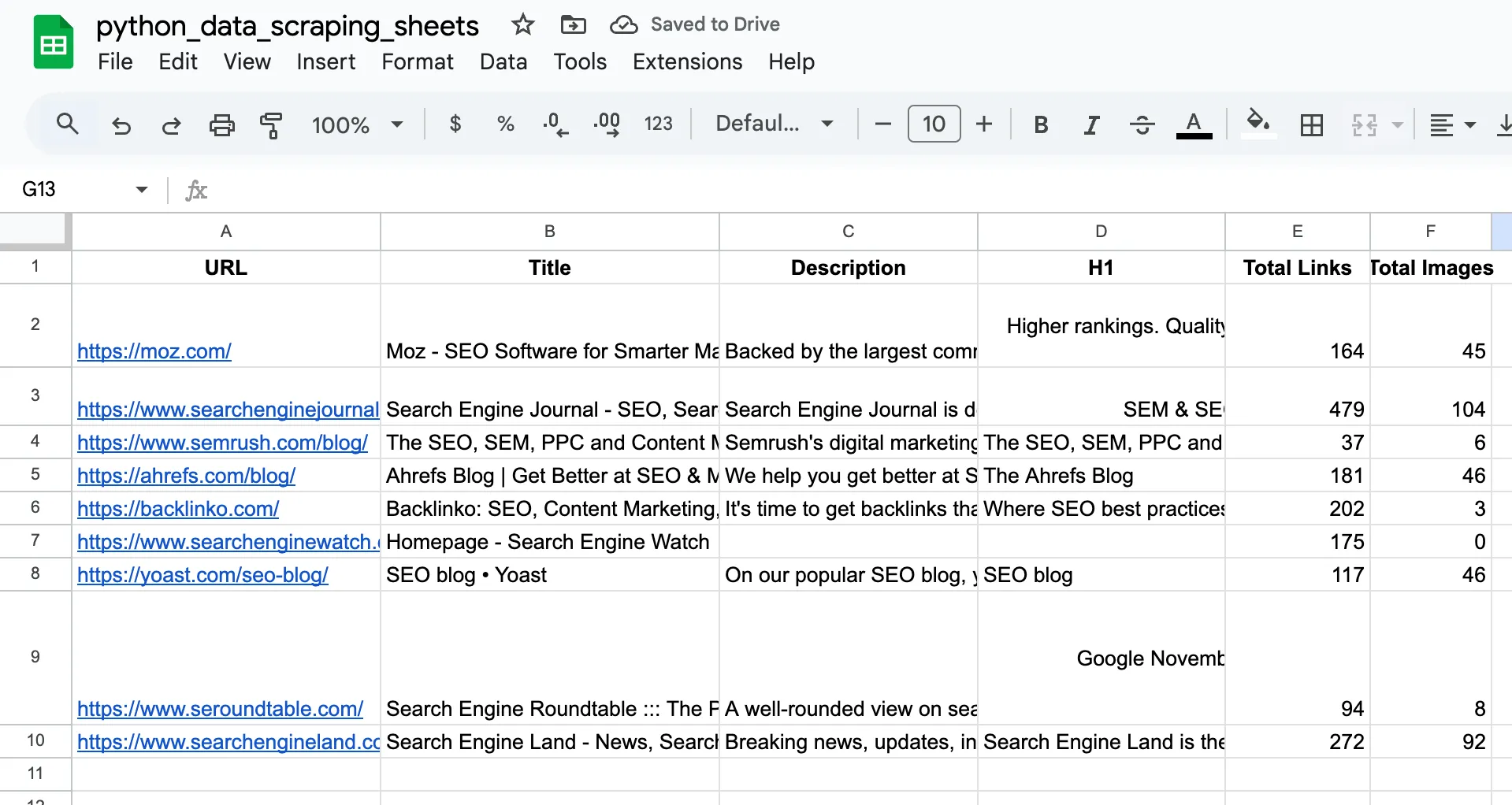
เห็นไหมครับ นี่คือข้อมูลที่เราไป scrape มาถูก save ลง Google Sheets เรียบร้อย เราสามารถนำข้อมูลไปวิเคราะห์หรือใช้งานต่อได้เลย
Tips สำหรับการใช้งาน
- การจัดการ Sheet: ควรสร้างหัวตาราง (header) ใน Google Sheets ให้ตรงกับข้อมูลที่จะดึง
- การเพิ่มข้อมูล: สามารถเพิ่มการดึงข้อมูลอื่น ๆ เช่น canonical tags, robots meta ตามที่เราต้องการ
- การจัดการ Error: ควรเพิ่ม try-except เพื่อจัดการกรณีเว็บไซต์ไม่มีการ response
- การทำ Automation: สามารถใช้ cron job เพื่อรันโค้ดอัตโนมัติแบบตั้งเวลาไว้ โดยที่เราไม่ต้องรันแบบ manual ทีละครั้ง
ข้อควรระวัง
- Rate Limiting: ควรเพิ่ม time.sleep() ระหว่างการดึงข้อมูลแต่ละเว็บ
- robots.txt: ตรวจสอบ robots.txt ก่อนดึงข้อมูล
- Credentials: เก็บไฟล์ client_secrets.json ให้ปลอดภัย
- Sheet Permissions: ต้องมีสิทธิ์ในการแก้ไข Google Sheets
การนำไปประยุกต์ใช้
- Competitor Analysis: ใช้วิเคราะห์โครงสร้างเว็บไซต์คู่แข่ง
- Content Audit: ตรวจสอบการใช้ headers และ meta tags
- Technical SEO: เพิ่มการตรวจสอบ technical issues
- Reporting: สร้างรายงาน SEO อัตโนมัติ
สรุป
โค้ดนี้เป็นพื้นฐานที่ดีสำหรับการเริ่มต้นใช้ Python ในงาน SEO สามารถนำไปพัฒนาต่อยอดให้เหมาะกับความต้องการได้ เช่น เพิ่มการวิเคราะห์ content, ตรวจสอบ performance หรือเชื่อมต่อกับ APIs อื่น ๆ
อย่าลืมปรับแต่ง code ให้เหมาะสมกับการใช้งานจริงนะครับตาม use case ของแต่ละคน และควรคำนึงถึงข้อกำหนดของเว็บไซต์ที่เราจะดึงข้อมูล เพื่อให้การทำงานมีประสิทธิภาพและไม่ส่งผลกระทบต่อเว็บไซต์ปลายทางนั่นเองครับ
สำหรับเพื่อน ๆ สมาชิกที่อยากเข้าใจการทำงาน Technical SEO เต็มรูปแบบและเข้าใจการเขียน coding script ต่าง ๆ เพื่อนำไปประยุกต์ใช้ในงานด้าน SEO และ Digital Marketing ต่อไป ตอนนี้คลาส 📒 Complete Web Marketing & Technical SEO ยังว่าง 1 ที่นั่งสุดท้ายนะครับ
