
robots.txt คือ text file อยู่ที่ root ของเว็บไซต์ เช่น example.com/robots.txt ใช้สำหรับควบคุมบอตของ search engines เช่น Google, Bing, Yandex, etc เกี่ยวกับหน้า URLs หน้าไหนที่อนุญาตหรือไม่อนุญาตให้บอตไปเก็บข้อมูล (crawl) ในเว็บไซต์ของเราไปทำการประมวลผล
ทำให้เว็บของเราประหยัดหรือควบคุม crawl budget ได้ ทำให้มั่นใจได้ว่า มีแต่ URLs หรือหน้าเว็บเพจคุณภาพ ที่มีโอกาสได้ traffic จริง ๆ ที่จะถูกนำไปแสดงผลในหน้า search result ในลำดับถัดไป
เพราะความจริงแล้ว ไม่ใช่ทุกหน้าเว็บเพจของเราที่จำเป็นต้องให้บอตมา crawl ครับ ดังนั้นการมีไฟล์ robots.txt จะทำให้เราสามารถควบคุมส่วนนี้ได้
Note: ถ้าพื้นฐาน SEO ยังไม่แน่น แนะนำศึกษาเพิ่มเติมในคอร์สเรียน SEO ฟรีของเราในส่วน SEO คืออะไร (ศาสตร์การ optimize web เพื่อติดหน้าแรก Google โดยไม่เสียค่าโฆษณา)
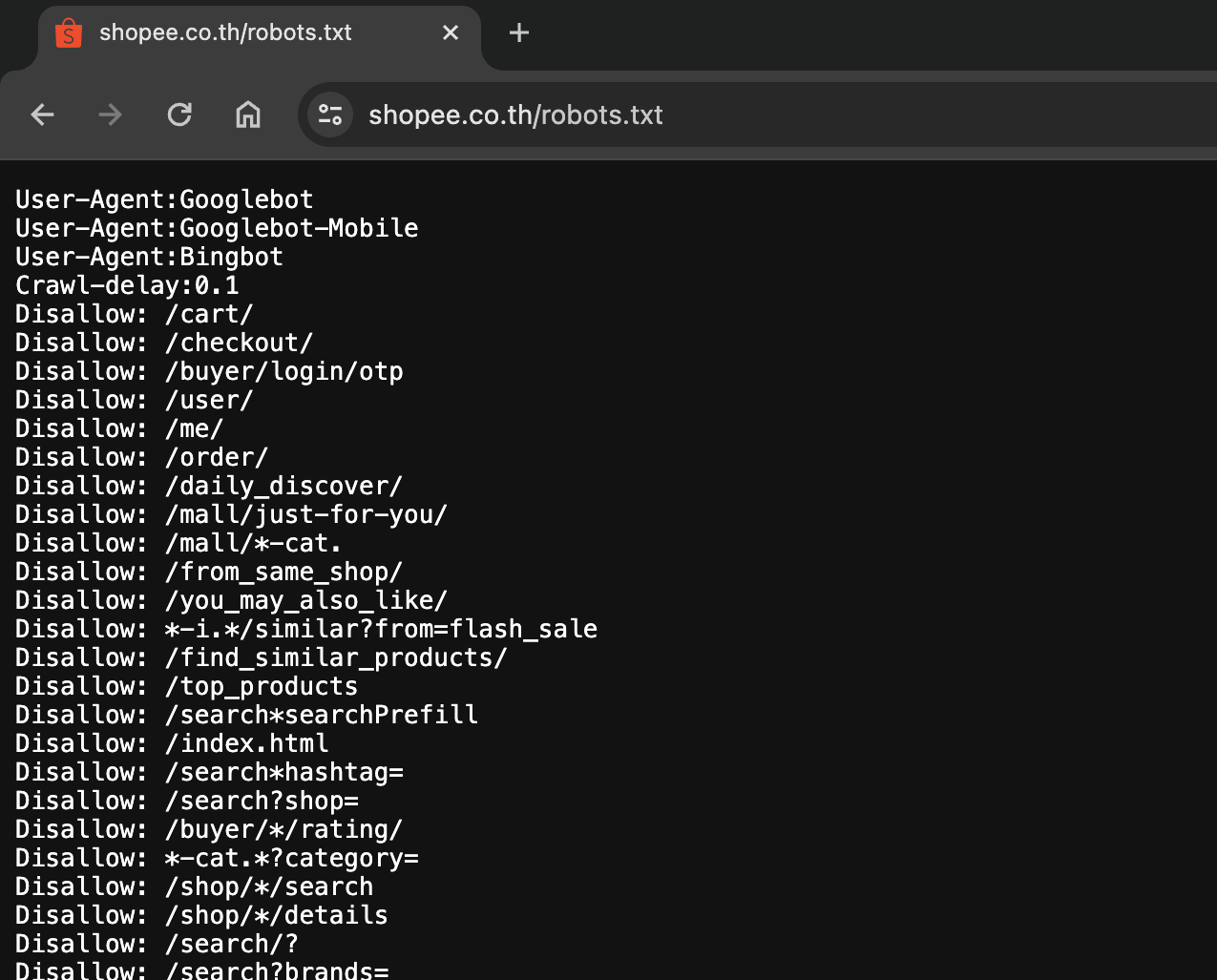 ตัวอย่าง robots.txt ของ Shopee
ตัวอย่าง robots.txt ของ Shopee
จากภาพด้านบนจะเห็นว่ามีการกำหนดชื่อบอตอยู่ 3 ตัว คือ
- Googlebot
- Googlebot-Mobile
- Bingbot
และนี่ก็คือบอตที่เรามักจะเห็นกันบ่อย ๆ ถ้าเราเปิด robots.txt โดยเฉพาะของเว็บใหญ่ ๆ ดู
- Googlebot (Google)
- Bingbot (Bing)
- Baiduspider (Baidu)
- Slurp Bot (Yahoo)
- Yandexbot (Yandex)
- DuckDuckBot (DuckDuckGo)
แน่นอนครับว่า Googlebot จะเป็นบอตที่เราเจอได้บ่อยสุด
ข้อดีของ robots.txt
ควบคุมการเข้าถึงของบอต: robots.txt ช่วยให้เจ้าของเว็บไซต์สามารถกำหนดได้ว่าหน้าไหนหรือไฟล์ไหนที่ไม่ต้องการให้บอตค้นหาหรือเข้าถึง เช่น ไฟล์ที่มีข้อมูลส่วนตัวหรือหน้าที่ไม่สำคัญสำหรับการทำ SEO เช่น หน้าแดชบอร์ดของผู้ใช้ ฯลฯ
ประหยัด banwidth & resources: ด้วยการป้องกันไม่ให้บอตเข้าถึงบางส่วนของเว็บไซต์ สามารถลดปริมาณการใช้แบนด์วิดท์และโหลดบนเซิร์ฟเวอร์ ทำให้เว็บไซต์ทำงานได้เร็วและมีประสิทธิภาพมากขึ้น คือเว็บเบาขึ้นนั่นเองครับ
ป้องกันการจัดอันดับของหน้าที่ไม่ต้องการ: บางครั้งหน้าเว็บบางหน้าที่ไม่ต้องการให้ถูกค้นหา เช่น หน้าที่ซ้ำกันหรือหน้าทดสอบ (เช่นหน้าที่อยู่ใน UAT ที่ยังไม่ใช่หน้าเว็บ production ใช้งานจริง สำหรับ software dev จะคุ้นเคยกับหน้านี้) สามารถใช้ robots.txt เพื่อป้องกันไม่ให้บอตจัดอันดับหน้าเหล่านี้
ช่วยปรับ SEO ranking: การใช้ robots.txt อย่างถูกต้องสามารถช่วยให้บอตของเสิร์ชเอนจินโฟกัสไปที่เนื้อหาหรือ URL ที่สำคัญและมีคุณภาพ ทำให้ช่วยในการปรับการจัดอันดับ SEO โดยรวมให้ดีขึ้นได้
โครงสร้างของ robots.txt
ไฟล์ robots.txt นั้นเป็นไฟล์รูปแบบ text file โดยให้ตั้งชื่อไฟล์เป็น "robots.txt" (ต้องชื่อนี้เท่านั้น) และนำไปอัปโหลดไว้ที่ หรือให้ทำการ map URL ไปที่ root ของเว็บไซต์ (ปกติ web dev จะทำส่วนนี้ให้เรา หรือไม่ถ้าเพื่อน ๆ ที่ใช้ WordPress ก็จะมีปลั๊กอินส่วนนี้ครับ)
โดยโครงสร้างของไฟล์ robots.txt ประกอบด้วยส่วนต่าง ๆ ดังนี้
User-agent
user-agent คือ ชื่อบอตของเสิร์ชเอนจินที่จะมา crawl หน้าเว็บ หากต้องการกำหนดกฎเฉพาะสำหรับบอตนั้น ๆ สามารถระบุ User-agent ของบอตนั้นได้ เช่น บอตที่นิยมที่สุดคือ Googlebot (สำหรับ Google), Bingbot (สำหรับ Bing) หรือ * (wildcard) สำหรับทุก Search Engines
User-agent: *Disallow
disallow คือ เส้นทาง (route) ของ URL ที่ไม่ควรให้เสิร์ชเอนจินค้นหาเข้าถึงหน้าใด ๆ บนเว็บไซต์ โดยเราสามารถกำหนด route ของ URL นั้นในส่วน Disallow เช่น Disallow: /admin/ จะหมายถึงไม่ควรให้ค้นหาหน้าใน /admin/ , /user/, ... /secret-page/ นั่นเอง ซึ่งอันนี้ก็สมเหตุสมผลใช่ไหมครับ เพราะไม่มีความจำเป็นที่จะให้บอตมาเก็บเกี่ยวหน้าแอดมินหรือหน้าที่ user ของเราเพื่อไปแสดงผลบน search result
และอีกหน้าที่ใช้บ่อยคือหน้าเสิร์ช ลองจินตนาการดูว่า ถ้าเว็บเรามีหน้าเสิร์ช เช่น /search?q='keyword' (q คือ URL พารามิเตอร์) โอกาสเป็นไปได้ของหน้าใหม่ ๆ ที่จะเกิดขึ้นนี่เรียกได้ว่า unlimited กันเลยทีเดียว ดังนั้นก็จัดการ Disallow หน้านี้ไว้โลด
# ห้ามเข้าถึงหน้าผู้ใช้และข้อมูลส่วนตัว Disallow: /user/ Disallow: /account/ Disallow: /profile/ Disallow: /dashboard/ # ห้ามเข้าถึงหน้าแอดมิน Disallow: /admin/ Disallow: /wp-admin/ # ห้ามเข้าถึงไฟล์และ directory เหล่านี้ Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /private/ Disallow: /.htaccess Disallow: /wp-includes/ # ห้ามเข้าถึงหน้าเสิร์ช Disallow: /search/ Disallow: /search?q=
Allow
allow คือ เส้นทาง (route) ของ URL ที่ต้องการอนุญาตให้เสิร์ชเอนจินทำการค้นหาหน้าใด ๆ ที่อยู่ใน route ที่ต้อง (หน้าที่ต้องการให้บอตมาเก็บข้อมูล)
ปกติท่าที่หลายคนใช้ก็คือ จะอนุญาตทั้งหมด โดยใช้เป็น Allow: / แล้วค่อยไป disallow ตัว path ที่ต้องการ ซึ่งอันนี้สะดวกกว่า เพราะปกติหน้าที่ต้อง disallow นั้นมีน้อยกว่าอยู่แล้ว (หรือบางทีก็ไม่จำเป็นต้องกำหนด Allow ก็ได้ เพราะมันเป็น default อยู่แล้วครับ กำหนดแค่ Disallow ก็พอ)
Allow: /Sitemap
คือ แผนผังของเว็บไซต์ ซึ่งเป็นไฟล์ที่เก็บรวบรวมลิงก์ทั้งหมดของเว็บที่เราต้องการ index เพื่อช่วยในการค้นหาลิงก์ในเว็บไซต์ของเราได้สะดวกมากยิ่งขึ้น
คือถ้าอยากให้ Googlebot มาเก็บเกี่ยวลิงก์เพื่อไป index อยู่เป็นประจำให้สร้างไฟล์ sitemap.xml เพื่อทำ sitemap ครับ เพราะเรายังสามารถกำหนดความถี่ที่จะให้บอตมา crawl หน้า URLs นั้น ๆ ได้ ไม่ว่าจะเป็น daily, weekly, monthly อะไรทำนองนี้
Sitemap: https://www.example.com/sitemap.xmlตัวอย่างไฟล์ Robots.txt แบบเต็ม
User-agent: *
# ห้ามเข้าถึงหน้าผู้ใช้และข้อมูลส่วนตัว
Disallow: /user/
Disallow: /account/
Disallow: /profile/
Disallow: /dashboard/
# ห้ามเข้าถึงหน้าแอดมิน
Disallow: /admin/
Disallow: /wp-admin/
# ห้ามเข้าถึงไฟล์และ directory เหล่านี้
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Disallow: /.htaccess
Disallow: /wp-includes/
# ห้ามเข้าถึงหน้าเสิร์ช
Disallow: /search/
Disallow: /search?q=
Sitemap: https://www.example.com/sitemap.xmlสิ่งที่ต้องระมัดระวัง
หากเว็บไซต์ของเรามีการเพิ่มไฟล์ robots.txt แต่ไม่ได้ตั้งค่าให้ถูกต้องนั้น ก็อาจจะส่งผลเสียมากกว่าผลดีได้เลย เช่น เผลอไป disallow หน้าที่ไม่ควร disallow ก็จะทำให้เกิดปัญหาที่บอตเข้ามาเก็บข้อมูลหน้านั้น ๆ ไม่ได้ จนทำให้เกิดปัญหาในการนำไป index ดังนั้นจึงต้องระมัดระวังในขั้นตอนนี้พอสมควร
สรุป
ควรตั้งค่าไฟล์ robots.txt อย่างระมัดระวัง ถ้าเป็นเว็บเล็ก ๆ มี URLs ไม่กี่หน้า ไม่มีส่วนที่ต้องซ่อนหน้า URL หรือต้องการให้หน้าเว็บไป index ทุกหน้าก็คิดว่าไม่จำเป็นต้องไปก็ได้ครับ (ตัวอย่าง เช่น contentmastery.io ก็ไม่ได้มีไฟล์นี้)
แต่ถ้าเว็บไซต์ขนาดกลาง ถึงเว็บใหญ่ ๆ ที่มี URLs เยอะมาก ๆ เป็นเว็บใหญ่ที่มี URLs ในระดับหลายพัน หมื่น แสนหรือล้านนี่ ก็คงควรต้องมีครับ เพื่อที่จะสามารถควบคุมและจัดการการ crawl ของบอต ซึ่งจะช่วยให้บอตมาเก็บข้อมูลหน้าเว็บที่สำคัญ ๆ และหน้าที่จำเป็นเท่านั้น เป็นผลให้ประสิทธิภาพ SEO และ visibility (การมองเห็น) ของเว็บไซต์เราดีขึ้นครับ
ที่มา
