
ปัญหา duplicate content เป็นอีกหนึ่งส่วนสำคัญที่คนทำ SEO หรือเจ้าของเว็บไซต์จะละเลยไปไม่ได้ ซึ่งหลายคนอาจจะยังไม่รู้ตัวว่า บทความหรือคอนเทนต์ที่เราเขียนอยู่กำลังมีเนื้อหาซ้ำอยู่ แต่พระเอกของเราวันนี้... Canonical Tag สามารถช่วยแก้ปัญหาจุดนี้ได้ครับ
Canonical Tag หรือ URL คืออะไร
ก่อนอื่นต้องนิยามให้ชัดเจนก่อนครับ ...
- Canonical URL คือ URL หลักหรือ URL ต้นฉบับที่เราต้องการให้ Google จดจำและแสดงผลในหน้าผลการค้นหา โดยเฉพาะในกรณีที่เว็บไซต์มีหน้าเว็บที่มีเนื้อหาเหมือนกันหรือคล้ายกันมากแต่สามารถเข้าถึงได้จากหลาย URL
- Canonical Tag คือ HTML tag ที่ใช้กำหนด URL หลักของหน้าเว็บ เพื่อบอก Google ว่า URL ไหนคือ URL ที่ควรแสดงในผลการค้นหา ช่วยแก้ปัญหา duplicate content
จะเห็นว่า
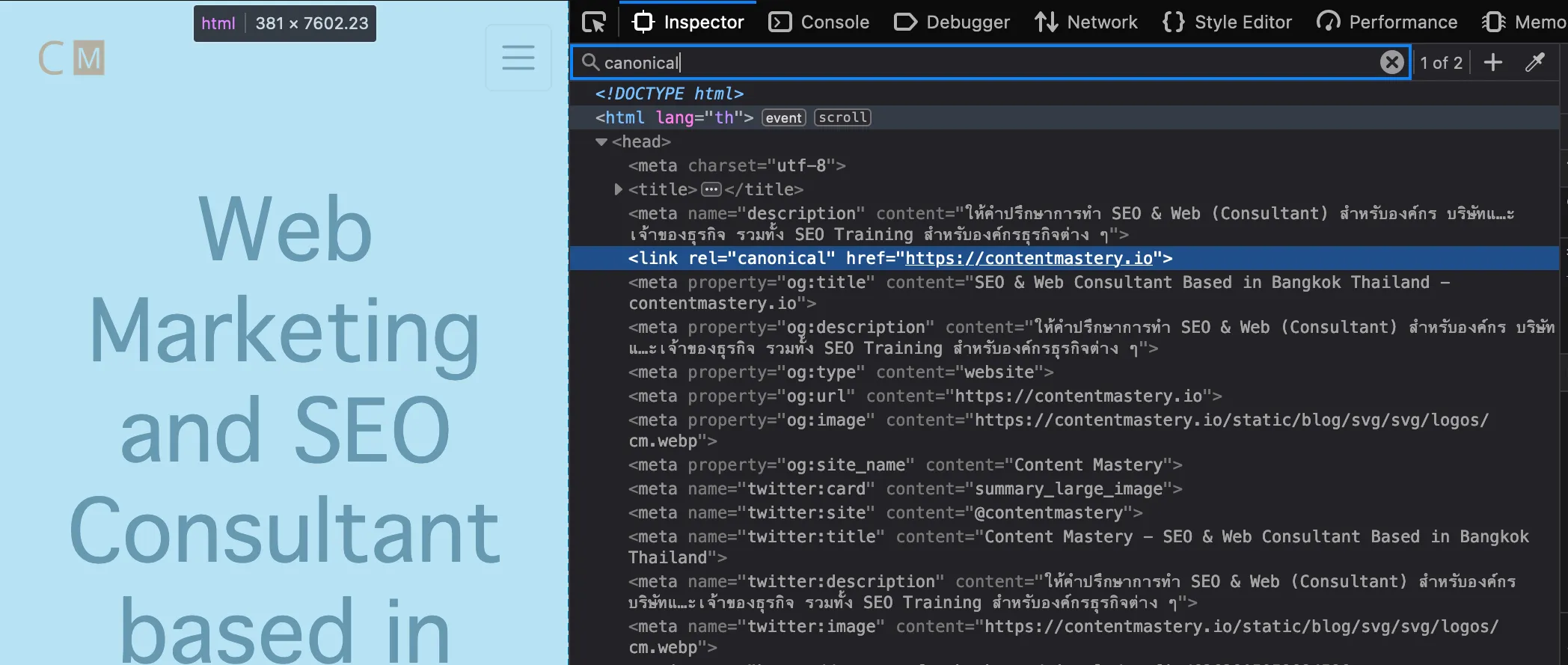
เมื่อพิจารณาจาก
<link rel="canonical" href="https://contentmastery.io">
และเมื่อแยกออกมา...
นี่คือ canonical URL (URL หลักที่เรากำหนด)
https://contentmastery.io
และนี่ Canonical tag (ก็คือเป็น rel attribute ของ HTML)
rel="canonical"ซึ่ง Canonical ยังจัดอยู่ในประเภทของ Technical SEO เพราะอาจจะต้องใช้ความรู้เชิงเทคนิคนิสสส
1 เว็บเพจที่เราเห็น มี URLs หลายเวอร์ชัน
โดยปกติแล้วสาเหตุมาจากหน้าเว็บของเรามีเนื้อหาที่คล้ายคลึง (หรือแม้แต่เนื้อหาเดียวกัน) แต่สามารถเข้าถึงได้ผ่าน URL หลายเวอร์ชัน
ตัวอย่าง เช่น สมมติว่าเรากำลังเขียนบทความ "10 คาเฟ่ที่ดีที่สุดในกรุงเทพ ฯ" ก็จะได้ URL ประมาณนี้
https://www.example.com/blog/top-10-cafes-in-bangkokแต่ที่จริงแล้ว ในเบื้องลึกเบื้องหลังเราอาจจะได้ URLs ตามด้านล่างนี้ครับ
https://www.example.com/blog/top-10-cafes-in-bangkok
http://www.example.com/blog/top-10-cafes-in-bangkok/
https://example.com/blog/top-10-cafes-in-bangkok
example.com/blog/top-10-cafes-in-bangkok
example.com/blog/top-10-cafes-in-bangkok/
https://www.example.com/blog/top-10-cafes-in-bangkok/index.html
https://www.example.com/blog/top-10-cafes-in-bangkokเห็นไหมครับว่า ถึงแม้จะเป็นบทความที่ถูกเขียนเพียงบทความเดียว แต่ในเบื้องหลังนั้นมันมี URLs หลายเวอร์ชันถูกสร้างขึ้นมา ทั้ง http, non-http, https, www, ฯลฯ สร้างความสับสนให้กับ Search Engine ได้เลย นำมาซึ่งปัญหาในการทำดัชนี (Indexing) และจัดอันดับ (Ranking) การค้นหา และประสิทธิภาพโดยรวมของ SEO
บทความแนะนำเพิ่มเติม: หลักการทำงานของ Search Engine
สาเหตุหลักที่เกิด Duplicate Content
อย่างที่ได้กล่าวไปในข้างต้นว่าเว็บไซต์ของเรานั้นมีโอกาสที่จะเกิดการซ้ำกันของเนื้อหาได้ ถ้าเราไม่ได้กำหนดแท็กเพื่อบอกเสิร์ชเอนจินว่า URL เวอร์ชันไหนคือ main version ของหน้าเว็บเพจนั้นของเรา
นี่คือสาเหตุต่าง ๆ ที่พบบ่อย ที่ทำให้เกิด Duplicate Content
- HTTP & HTTPS: ก็คือสาเหตุที่พบได้บ่อยที่สุดเลยก็ว่าได้ โดยในเบื้องต้นแก้ได้ด้วยการกำหนดให้เนื้อหาทั้งหมดเข้าถึงผ่าน HTTPS เท่านั้นโดยกำหนด rel="canonical" ดังตัวอย่างโค้ดที่ได้กล่าวไปด้านบน (ซึ่งส่วนนี้เรียกว่าการทำ Self-referencing Canonical) และส่วนนี้จะรวมไปถึงการที่เว็บของเราเดิมเป็น http แล้วอัปเดตไปเป็น https ก็ทำให้เกิดปัญหาคอนเทนต์ซ้ำ (ก็ให้ทำ 301 Redirect ไปที่ https ครับ)
- Cross-Domain Duplicates : บางเว็บไซต์อาจจะมีบทความหรือคอนเทนต์ที่เนื้อหาแบบเดียวกันแล้ว publish ไปหลาย ๆ ที่ ซึ่งอันนี้ทำให้เห็นปัญหาเนื้อหาซ้ำได้แบบชัดเจนเลยก็ว่าได้ (ตัวอย่างเว็บ medium.com จะมีฟีเจอร์ที่จัดการส่วนนี้ ที่ให้เราสามารถนำบทความต้นฉบับในเว็บเราไปโพสต์บนเว็บ Medium ได้ โดยไม่เกิดปัญหา Duplicate Content)
อีกสาเหตุที่มีความเป็นไปได้สูงที่จะเกิดเนื้อหาที่ซ้ำกันได้คือการทำ Programmatic SEO (ซึ่งส่วนนี้ต้องวางแผนให้ดีและทำอย่างระมัดระวัง)
วิธีตรวจเช็คปัญหา Canonical/Duplicate Content
วิธีการเช็คว่าเว็บของเราเกิดปํญหานี้อยู่หรือไม่ ก็สามารถเช็คได้ผ่าน Google Search Console ได้เลยครับ
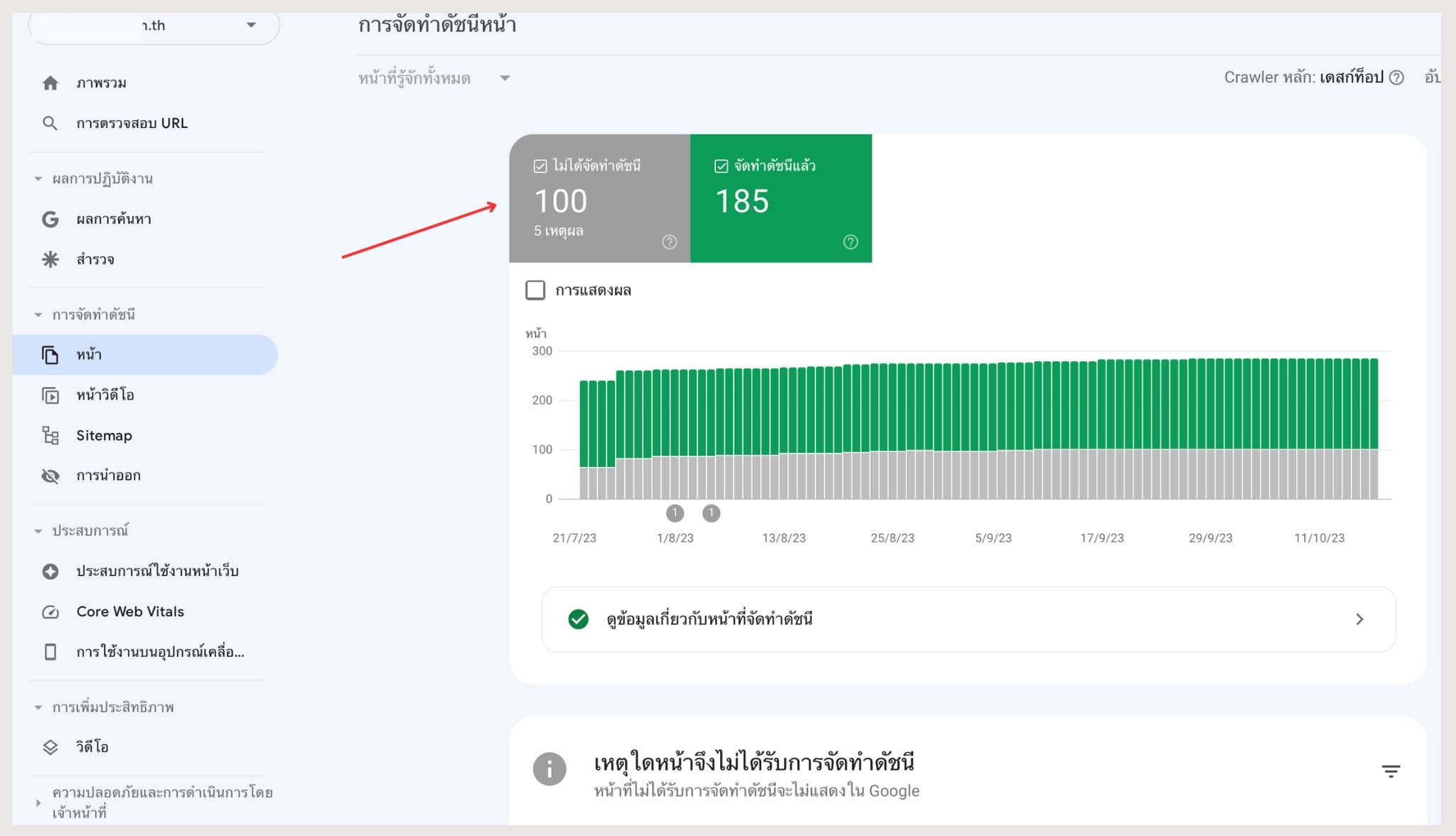
Google Search Console แสดงผลเนื้อหาที่ไม่ได้ถูก Index
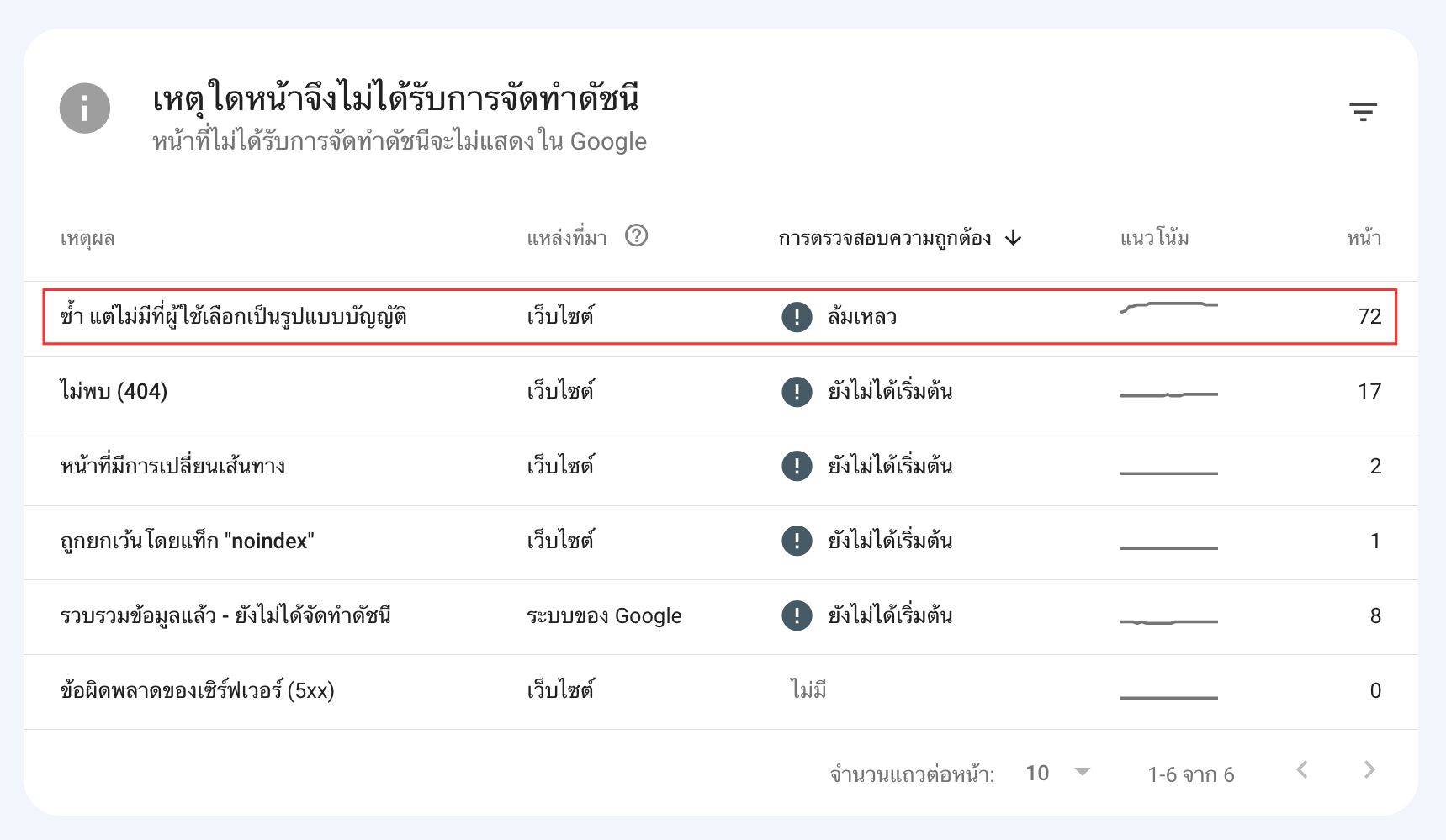
แสดงหน้าที่เป็นปัญหา Canonicalization
แก้ได้ด้วย Canonical Tag, ทำ 301 Redirect & Noindex
- Canonical Tag: ในส่วนของ HTML จะมีแท็กที่เรียกว่า "Canonical Tag" เพื่อให้เรากำหนดเวอร์ชันของ URL ที่ต้องการเป็น Canonical เวอร์ชันได้ โดยสามารถเพิ่มโค้ด rel="canonical" เข้าไปในส่วนของ <head> ได้เลย ซึ่งการทำแบบนี้เรียกว่า Self-referencing Canonical Tag
<head>
<title>Top 5 Cafes in Bangkok You Should Visit | Cafe Review</title>
....
<link rel="canonical" href="https://www.example.com/blog/top-5-cafes-in-bangkok">
...
</head>จะใช้แบบมี www หรือไม่มี non-www ก็ได้เช่นกัน แต่ต้องใช้ให้เหมือนกันทั้งเว็บครับ ตัวอย่างเว็บเครื่องมือและผู้นำด้าน SEO อย่าง Ahrefs (ใช้แบบไม่มี www) ส่วน Semrush (ใช้แบบมี www) ซึ่งก็ยังไม่มีข้อมูลที่ชัดเจนว่าแบบไหนดีที่สุด แต่ใช้ให้เป็นแบบเดียวกันทั้งเว็บคือจบ!!
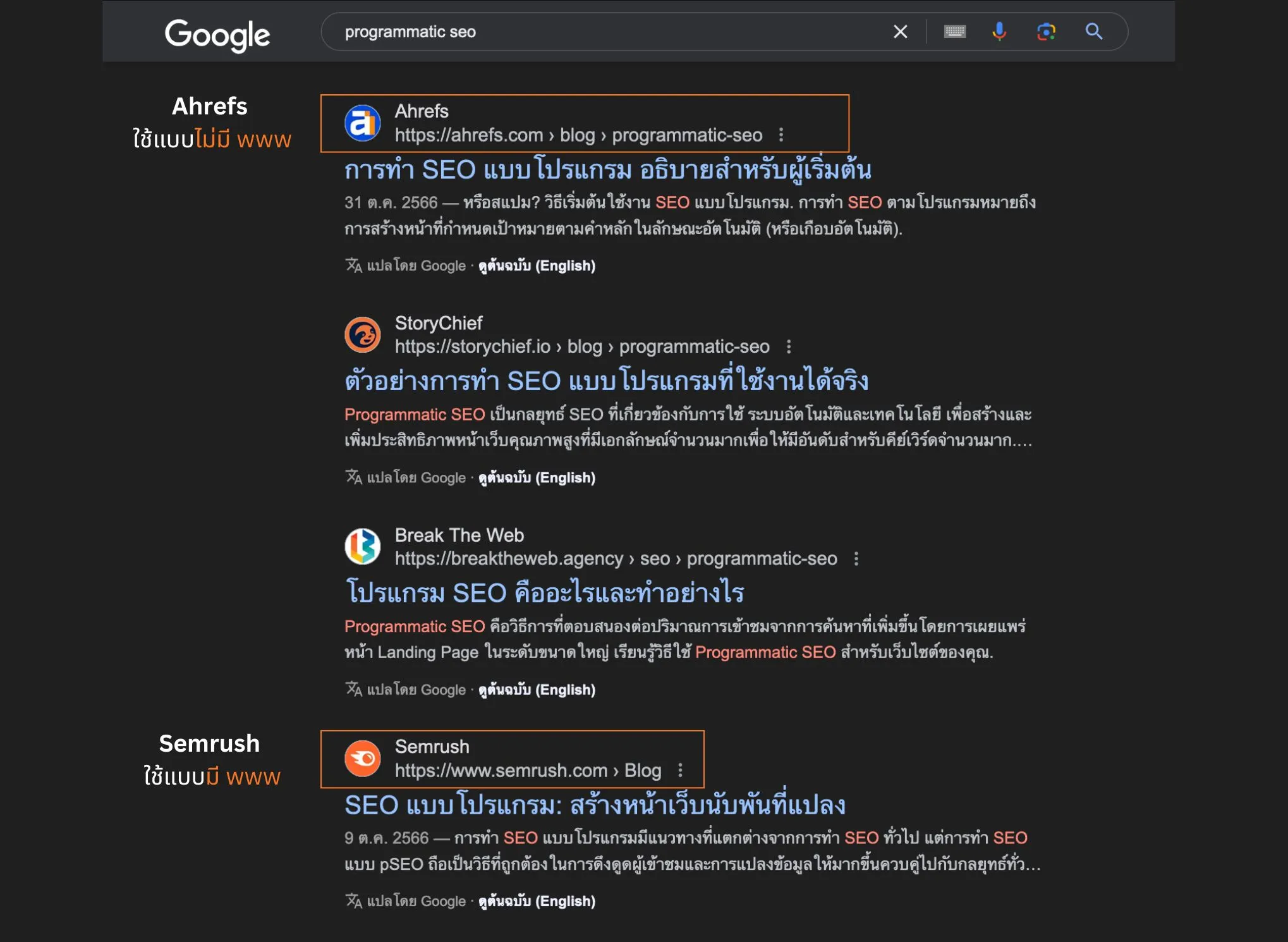
แท็กนี้จะเป็นการบอกเสิร์ชเอนจินว่า
https://www.example.com/blog/top-10-cafes-in-bangkokนี่คือเวอร์ชันหลักที่เราต้องการให้ Google เลือกไปทำ index นะ (โดยปกติแล้วก็มักจะใช้ URL แบบที่มี https) และเป็น URL แบบเต็ม (Absolute URL)
ลองดูเว็บอื่น ๆ เทียบดูก็ได้ครับ เช่นเว็บ SEO ระดับโลกอย่าง Search Engine Journal
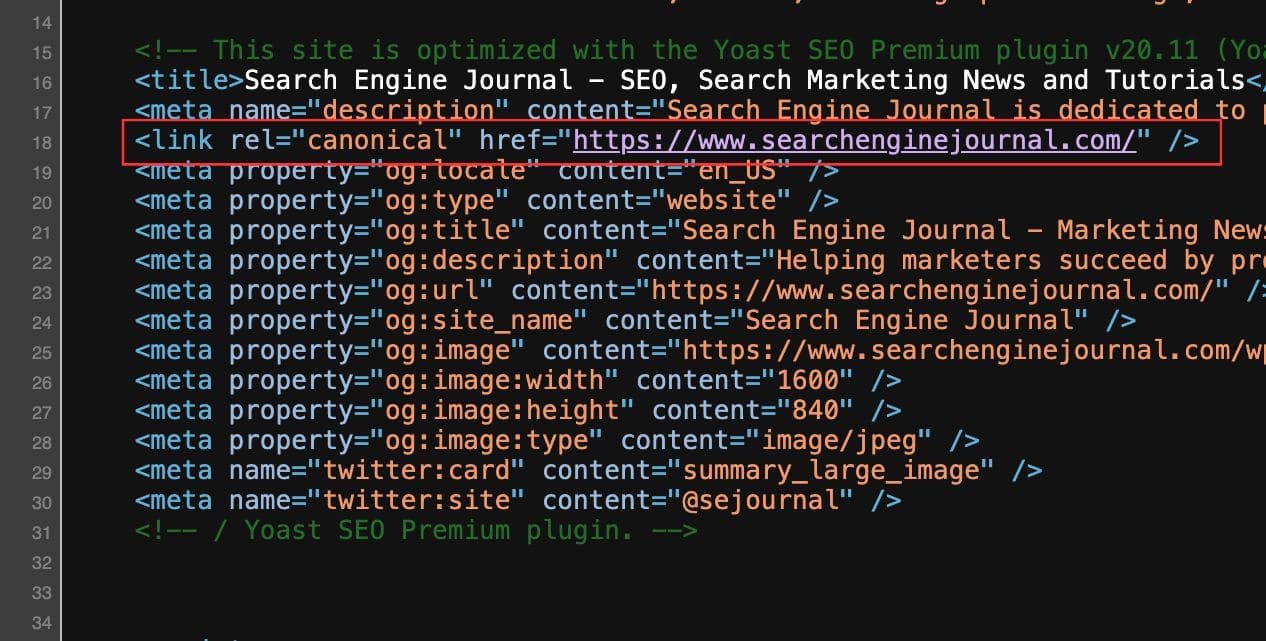
ตัวอย่างเว็บ Search Engine Journal
โค้ด
<link rel="canonical" href="https://www.searchenginejournal.com/" />นอกจากวิธีด้านบนที่ว่ามานี้เรายังสามารถทำ URL 301 Redirect (กรณี duplicate content จริงจัง คือหน้าเว็บมีเนื้อหาคล้ายคลึงกัน ก็อาจจะลบหน้านั้น แล้วทำ 301 ไปหน้าที่ต้องการแทน จะได้ไม่แย่งกันทำอันดับ)
หรือไม่ว่าจะเป็น Noindex ได้เช่นกัน (แต่ต้องทำอย่างระมัดระวังหรือให้ผู้ที่มีความเชี่ยวชาญทำเท่านั้นครับ ไม่งั้นทำผิดพลาดอาจสร้างผลกระทบทางลบต่อเว็บไซต์ได้เลย
การทำ 301 redirect เราจะไม่เห็น URL ต้นทางหรือหน้าเว็บเพจนั้นอีกต่อไปนะครับ เช่น mywebsite.com/page-a/ จะ redirect ไปที่ mywebsite.com/page-b/ เราจะเห็นเนื้อหาของหน้าเว็บของอันหลังคือเพจ mywebsite.com/page-b/ เท่านั้น แต่ถ้าทำ Canonical เราจะสามารถเข้าหน้าเว็บ my.../page-a/ ได้อยู่ ซึ่งอันนี้เราก้ต้องชั่งน้ำหนักส่วนนี้ให้ดีนะครับ
แล้วเราจะเพิ่มโค้ด Canonical Tag ตัวนี้เข้าไปในเว็บเราได้ยังไง ?
อันนี้ก็ขึ้นอยู่กับเครื่องมือที่เราใช้ทำเว็บกันแล้วครับ ถ้าแบบเว็บที่เขียนโค้ดนั้นก็สามารถ manual โค้ดเข้าไปได้เลย แต่ถ้าเป็นเว็บที่สร้างแบบสำเร็จรูปหรือจำพวก web builders ต่าง ๆ เช่น WordPress, Wix, Weebly, etc ก็คิดว่าน่าจะมีปลั๊กอินที่รองรับส่วนนี้อยู่แล้ว
ข้อดีหลังจากแก้ปัญหา Canonicalization
- เพิ่มประสิทธิภาพ SEO: ช่วยให้เสิร์ชเอนจินโฟกัสไปที่เนื้อหาหลัก ไปเก็บเกี่ยวข้อมูลใน URL ที่เราต้องการได้แบบเนื้อ ๆ เน้น ๆ
- รักษาค่าพลังลิงก์ (Link Equity): ทุก ๆ ลิงก์จะถูกชี้ไป URL เวอร์ชันที่ทำ Canonicalization ซึ่งสามารถคงไว้ซึ่งค่าพลังของลิงค์ไม่กระจายพลังออกไปหลาย ๆ ลิงก์ที่เนื้อหาซ้ำกัน
และอีกอย่าง Google Search Console จะไม่แสดงผลหรือรายงานปัญหานี้อีกต่อไป !! และมันจะไม่รกหูรกตาเราอีกครับ lol
สรุป
การแก้ปัญหา duplicate content เป็นอีกส่วนที่จำเป็นของการทำ SEO ซึ่งช่วยให้เราหมดกังวลเกี่ยวกับปัญหา Duplicate Content ทั้งยังช่วยเพิ่มประสิทธิภาพการค้นหาของเว็บไซต์ของเราให้ดีต่อเสิร์ชเอนจินมากยิ่งขึ้น
เรามักจะเจอได้บ่อยสำหรับเว็บไซต์อีคอมเมิร์ซที่มีหน้าสินค้าหลากหลาย อาจเจอปัญหา Duplicate Content สูง ดังนั้นการทำ Ecommerce SEO ต้องคำนึงถึง Canonical Tag เป็นพิเศษเพื่อแก้ไขปัญหานี้
วิธีแก้ปัญหา Dupliate Content ทำได้โดยการกำหนด Canonical Tag, ทำ URL 301 Redirect หรือแม้แต่ Noindex แท็ก (บางกรณีเท่านั้น) จะช่วยเสิร์ชเอนจินเลือก URL ที่ดีที่สุด หรือไม่ว่าจะเป็น URL ปลายทางที่เราต้องการ ในการนำไปจัดทำ index ต่อไป ซึ่งจะช่วยปรับปรุงให้ SEO Score ของเว็บเราดีขึ้นได้อย่างแน่นอนครับ
✅ แต่ถ้าเพื่อน ๆ ต้องการเข้าใจการทำ SEO แบบทะลุปรุโปร่งในทุกมิติ โดยเฉพาะด้าน Technical SEO เตรียมพบกับคลาสสดรอบสุดท้ายของปี จัดหนักจัดเต็มกันไปเลยเร็ว ๆ นี้ (สามารถ inbox มาสอบถามรายละเอียดหรือจองก่อนได้ครับ)
