robots.txt คือ ไฟล์ที่ใช้บอกบอตของ search engines เช่น Google, Bing, Yandex, etc เกี่ยวกับเนื้อหาที่ควรและไม่ควรให้ bots เหล่านี้ว่า หน้าไหนควรให้บอตไปเก็บข้อมูล หน้าไหนไม่ควรให้บอตไปเก็บ (มา crawl) ในเว็บไซต์ของเราไปทำการ index ซึ่งทำให้เว็บของเราประหยัดหรือควบคุม crawl budget ได้ ทำให้มั่นใจได้ว่า มีแต่ URLs หรือหน้าเว็บเพจคุณภาพ ที่มีโอกาสได้ traffic จริง ๆ ที่จะถูกนำไปแสดงผลในหน้า search result ในลำดับถัดไป
ซึ่งไฟล์นี้จะถูกตั้งค่าและอัปโหลดไว้ที่ root ของเว็บไซต์ เช่น example.com/robots.txt
Note: ถ้าพื้นฐาน SEO ยังไม่แน่น แนะนำศึกษาเพิ่มเติมในคอร์สเรียน SEO ฟรีของเราในส่วน SEO คืออะไร (ศาสตร์การ optimize web เพื่อติดหน้าแรก Google โดยไม่เสียค่าโฆษณา)
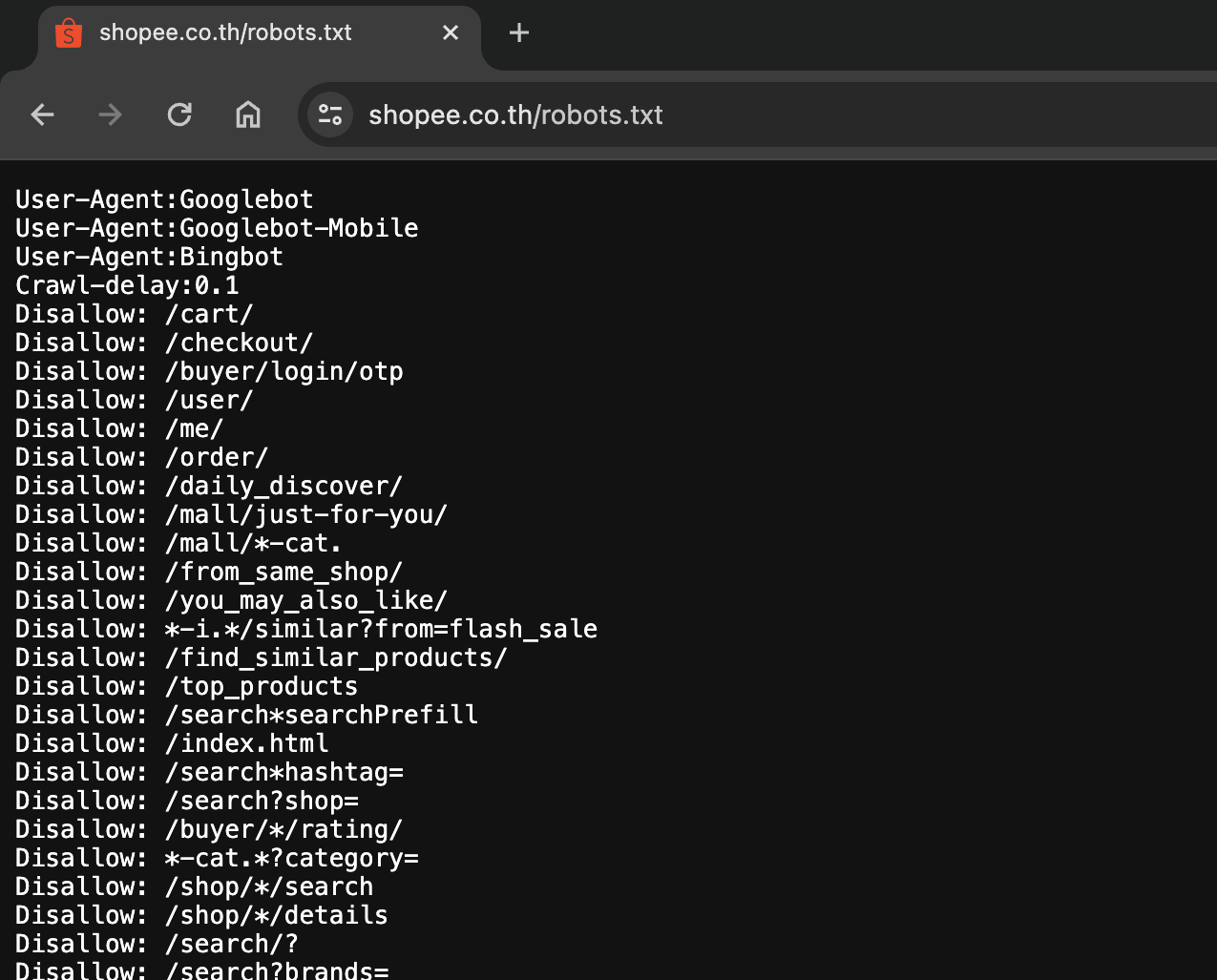 ตัวอย่าง robots.txt ของ Shopee
ตัวอย่าง robots.txt ของ Shopee
จากภาพด้านบนจะเห็นว่ามีการกำหนดชื่อบอตอยู่ 3 ตัว คือ
- Googlebot
- Googlebot-Mobile
- Bingbot
และนี่ก็คือบอตที่เรามักจะเห็นกันบ่อย ๆ ถ้าเราเปิด robots.txt โดยเฉพาะของเว็บใหญ่ ๆ ดู
- Googlebot (Google)
- Bingbot (Bing)
- Baiduspider (Baidu)
- Slurp Bot (Yahoo)
- Yandexbot (Yandex)
- DuckDuckBot (DuckDuckGo)
แน่นอนครับว่า Googlebot จะเป็นบอตที่เราเจอได้บ่อยสุด
ข้อดีของ robots.txt
ควบคุมการเข้าถึงของบอต: robots.txt ช่วยให้เจ้าของเว็บไซต์สามารถกำหนดได้ว่าหน้าไหนหรือไฟล์ไหนที่ไม่ต้องการให้บอตค้นหาหรือเข้าถึง เช่น ไฟล์ที่มีข้อมูลส่วนตัวหรือหน้าที่ไม่สำคัญสำหรับการทำ SEO เช่น หน้าแดชบอร์ดของผู้ใช้ ฯลฯ
ประหยัดแบนด์วิดท์และทรัพยากร: ด้วยการป้องกันไม่ให้บอตเข้าถึงบางส่วนของเว็บไซต์ สามารถลดปริมาณการใช้แบนด์วิดท์และโหลดบนเซิร์ฟเวอร์ ทำให้เว็บไซต์ทำงานได้เร็วและมีประสิทธิภาพมากขึ้น
ป้องกันการจัดอันดับของหน้าที่ไม่ต้องการ: บางครั้งหน้าเว็บบางหน้าที่ไม่ต้องการให้ถูกค้นหา เช่น หน้าที่ซ้ำกันหรือหน้าทดสอบ สามารถใช้ robots.txt เพื่อป้องกันไม่ให้บอตจัดอันดับหน้าเหล่านี้
ปรับปรุงการจัดอันดับ SEO: การใช้ robots.txt อย่างถูกต้องสามารถช่วยให้บอทของเสิร์ชเอนจินสามารถโฟกัสไปที่เนื้อหาที่สำคัญและมีคุณภาพ สามารถช่วยในการปรับการจัดอันดับ SEO โดยรวมได้
ให้ข้อมูลแก่บอตที่แตกต่างกัน: robots.txt สามารถกำหนดกฎเฉพาะสำหรับบอทต่าง ๆ เพื่อให้ข้อมูลที่แตกต่างกันสำหรับบอตของแต่ละเสิร์ชเอนจิน เช่น อนุญาตให้บอตของ Google เข้าถึงเนื้อหาบางส่วน
โครงสร้างของ robots.txt
ไฟล์ robots.txt นั้นเป็นไฟล์รูปแบบ text file ซึ่งสามารถสร้างและแก้ไขด้วย (text editor) เช่น Notepad หรือ Visual Studio Code โดยให้ตั้งชื่อไฟล์เป็น "robots.txt" และนำไปอัปโหลดไว้ที่ หรือให้ทำการ map URL ไปที่ root ของเว็บไซต์
โดยโครงสร้างของไฟล์ robots.txt ประกอบด้วยส่วนต่าง ๆ ดังนี้
User-agent
user-agent คือ ชื่อบอตของเสิร์ชเอนจินที่จะมา crawl หน้าเว็บ หากต้องการกำหนดกฎเฉพาะสำหรับบอตนั้น ๆ สามารถระบุ User-agent ของบอตนั้นได้ เช่น บอตที่นิยมที่สุดคือ Googlebot (สำหรับ Google), Bingbot (สำหรับ Bing) หรือ * (wildcard) สำหรับทุก Search Engines
Disallow
disallow คือ เส้นทาง (route) ของ URL ที่ไม่ควรให้เสิร์ชเอนจินค้นหาเข้าถึงหน้าใด ๆ บนเว็บไซต์ โดยเราสามารถกำหนด route ของ URL นั้นในส่วน Disallow เช่น Disallow: /admin/ จะหมายถึงไม่ควรให้ค้นหาหน้าใน /admin/ ซึ่งอันนี้ก็สมเหตุสมผลใช่ไหมครับ เพราะไม่มีความจำเป็นที่จะให้บอตมาเก็บเกี่ยวหน้าแอดมินของเราเพื่อไปแสดงผลบน search result
Allow
allow คือ เส้นทาง (route) ของ URL ที่ต้องการอนุญาตให้เสิร์ชเอนจินทำการค้นหาหน้าใด ๆ ที่อยู่ใน route ที่ต้อง Disallow เช่น Allow: /images/ จะหมายถึงให้ค้นหาหน้าใน /images/ (คือให้ไปค้นหาในหน้านี้ได้นั่นเอง)
Sitemap
คือ URL ของแผนผังของเว็บไซต์ ซึ่งเป็นไฟล์ที่เก็บรวบรวมลิงก์ทั้งหมดของเว็บเพื่อช่วยในการค้นหาลิงก์ในเว็บไซต์ของเราได้สะดวกมากยิ่งขึ้น คือถ้าอยากให้ Googlebot มาเก็บเกี่ยวลิงก์เพื่อไป index อยู่เป็นประจำให้สร้างไฟล์ sitemap.xml เพื่อทำ sitemap ครับ เพราะเรายังสามารถกำหนดความถี่ที่จะให้บอตมา crawl หน้า URLs นั้น ๆ ได้
ตัวอย่างไฟล์ Robots.txt
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /images/
Sitemap: https://www.example.com/sitemap.xmlจำเป็นต้องมีหรือไม่?
โดยหากเว็บไซต์ของเรามีการเพิ่มไฟล์ robots.txt แต่ไม่ได้ตั้งค่าให้ถูกต้องนั้น ก็อาจจะส่งผลเสียมากกว่าผลดีได้เลย ดังนั้นจึงต้องระมัดระวังในขั้นตอนนี้พอสมควร
โดยแนะนำว่าควรมีสกิลด้าน
technical ในระดับหนึ่งครับหรือถ้าใครที่มี dev อยู่ในทีมก็ควรประสานงานร่วมกับ dev เพื่อให้ช่วยจัดการส่วนนี้ให้และอธิบายแนวทางไปให้
สรุป
ควรตั้งค่าไฟล์ robots.txt อย่างระมัดระวัง ถ้าเป็นเว็บเล็ก ๆ มี URLs ไม่กี่หน้าก็คิดว่าไม่จำเป็นต้องไปก็ได้ครับ robots.txt แต่ถ้าเว็บไซต์ของเรามี URLs เยอะมาก ๆ ในระดับหลายพัน หมื่น แสนหรือล้านนี่ ก็จำเป็นต้องมีและควรตรวจสอบให้แน่ใจว่าเสิร์ชเอนจินสามารถเข้าถึงเนื้อหาที่ควรค้นหาและเนื้อหาที่ไม่ควรเข้าถึงได้อย่างถูกต้องนะครับ
ที่มา